Introduction
One of the key creative aspects of an advertisement is choosing the image that will appear alongside the advertisement text. The advertisers aim is to select an image that will draw the attention of the users and will get them to click on it, while remaining relevant to the advertisement text (naturally, an image of a cute puppy next to an advertisement about insurance doesn’t make much sense) . Below are some examples of advertisements appearing in Taboola’s “Promoted Links” box. Notice that each advertisement contains both a title and an appealing image.
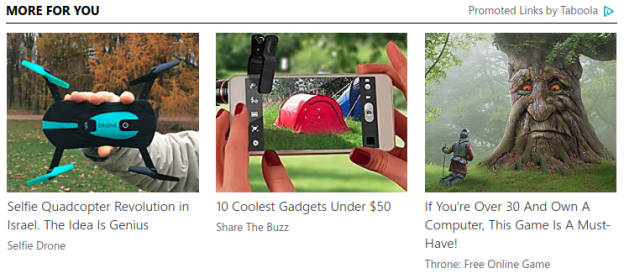
Examples of advertisements placed in Taboola’s “Promoted Links” box. Notice that each advertisement contains both a title and an appealing image.
Given an advertisement title (for example “15 healthy dishes you must try”), the advertiser has endless possibilities of choosing the image thumbnail to accompany it, clearly some more clickable than others. One can apply best practices in choosing the thumbnail, but manually searching for the best image (out of possibly thousands that fit a given title) is time consuming and impractical. Moreover, there is no clear way of quantifying how much a given image is related to a title and more importantly – how clickable the image is, compared to other options.
To Alleviate this problem, we developed a text to image search algorithm that given a proposed title, scans an image gallery to find the most suitable images and estimates their expected click through rate (a common marketing metric depicting the amount of user clicks per a fixed number of advertisement displays).
For example, here are the images returned by our algorithm for the query title “15 healthy dishes you must try” along with their predicted Click Through Ratio (CTR):

Examples of images returned by our algorithm for the title query “15 healthy dishes you must try” along with their predicted Click Through Ratio (CTR). Notice that the images nicely fit the semantics of title.








