In this post I will explain how to add a simple rotation invariance mechanism to the BRIEF[1] descriptor, I will present evaluation results showing the rotation invariant BRIEF significantly outperforms regular BRIEF where visual geometric changes are present and finally I will post a C++ implementation integrated into OpenCV3.
Just as a reminder, we had a general post on local image descriptors, an introductory post to binary descriptors and a post presenting the BRIEF descriptor. We also had posts on other binary descriptors: ORB[2], BRISK[3] and FREAK[4].
We’ll start by a visual example, displaying the correct matches between a pair of images of the same scene, taken from different angles – once with the original version of BRIEF (first image pair) and one with the proposed rotation invariant version of BRIEF (second image pair):

Correct matches when using the BRIEF descriptor

Correct matches when using the rotation invariant BRIEF descriptor
It can be seen that there are much more correct matches when using the proposed rotation invariant of the BRIEF descriptor.
The BRIEF descriptor
The BRIEF descriptor is one the simplest of the binary descriptors and also the first published. BRIEF operates by comparing the same set of smoothed pixel pairs for each local patch that it describes. For each pair, if the first smoothed pixel’s intensity is larger than that of the second BRIEF writes 1 in the final descriptor’s string, and 0 otherwise. The sampling pairs are chosen randomly, initialized only once and used for each image and local patch. As usual, the distance between two binary descriptors is computed as the number of different bits, and can be formally written as sum(XOR(descriptor1, descriptor2)).
Adding rotation invariance
Our method for adding rotation invariance is straightforward and uses the detector coupled with the descriptor. Many keypoint detectors can estimate the patch’s orientation (e.g. SIFT[5] and SURF[6]) and we can make use of that estimate to properly align the sampling pairs. For each patch, given the angle of the patch, we can rotate the sampling pairs according to the patch’s orientation and thus extract rotation invariant descriptors. The same principle is applied in the original implementation of the other rotation invariant binary descriptors (ORB, BRISK and FREAK), but as opposed to them we just take the orientation of the patch from the keypoint detector instead of devising some orientation measurement mechanism.
Experiments setup
Now for the fun part – comparing rotation invariance BRIEF with BRIEF’s original version. I’ll also compare to SIFT to see how binary descriptors compete with some of the floating point descriptors.
For the evaluation, I’ll use the Mikolajczyk benchmark [8] which is a publicly available and standard benchmark for evaluating local descriptors. The benchmark consists of 8 image sets, each containing 6 images that depict an increasing degree of a certain image transformation. Each set depicts a different transformation:
- Bark – zoom + rotation changes.
- Bikes – blur changes.
- Boat – zoom + rotation changes.
- Graffiti – view point changes.
- Leuven – illumination changes.
- Trees – blur changes.
- UBC – JPEG compression
- Wall – view point changes.
Below are the images of each set in the benchmark. In each set, the images are ordered from left to right and top to bottom (the first row contains images 1-3, the second row contains images 4-6).
Bark (zoom and rotation changes):

Bark – zoom and rotation changes
Bikes (blur): you can notice that image 6 is far more blurred than image 1.

Bikes – increasing blur
Boat (zoom and rotation changes):

Boat – zoom and rotation changes
Graffiti (view point changes):

Graffiti – view point changes
Leuven (illumination changes):

Leuven – illumination changes)
Trees (blur):

Trees – increasing blur
UBC (JPEG compression):

UBC – JPEG compression artifacts
Wall (viewpoint changes):

Wall – viewpoint changes
The protocol for the benchmark is the following: in each set, we detect keypoints and extract descriptors from each of the images, compare the first image to each of the remaining five images and check for correspondences. The benchmark includes known ground truth transformations (homographies) between the images, thus we can compute the percent of the correct matches and display the performance of each descriptor using recall vs. 1-precision curves.
I used the public OpenCV implementation[9] for our experiments. SIFT is used as a keypoint detector and I used the 512 bits version of BRIEF and rotation invariant BRIEF.
Results
Below are tables summarizing the area under the recall vs. precision curve for each of the sets, averaged over the five image pairs – higher values means the descriptor performs better. For clarity, I also specified the type of image transformation introduced by each set.
| Descriptor | Bark (zoom + rotation) | Bikes (blur) | Boat (zoom + rotation) | Graffiti (view point changes) |
| BRIEF | 0.007 | 0.677 | 0.048 | 0.097 |
| Rotation Invariant BRIEF | 0.055 | 0.353 | 0.05 | 0.103 |
| SIFT | 0.077 | 0.322 | 0.08 | 0.128 |
| Descriptor | Leuven (illumination) | Trees (blur) | UBC (JPEG compression) | Wall (view point changes) |
| BRIEF | 0.457 | 0.258 | 0.421 | 0.285 |
| Rotation Invariant BRIEF | 0.228 | 0.061 | 0.178 | 0.146 |
| SIFT | 0.131 | 0.048 | 0.13 | 0.132 |
Notice that for sets that depict orientation changes (Bark and Boat), the rotation invariant version of BRIEF performs much better than the original (not invariant) version. However, in sets that depict photometric changes (blur, illumination and JPEG compression) and do not depict orientation changes, the original version of BRIEF performs better than the rotation invariant one. It seems that when orientation changes are not present, trying to compensate for them introduces noise and reduces performance. Notice also that since the set Graffiti introduces some orientation changes (as can be seen from the images above), the rotation invariant version of BRIEF has an advantage over the original version of BRIEF. One can also see that although the “Wall” set exhibit view point changes, the images in the set have very much the same orientation, thus the rotation invariant version of BRIEF performs worse than the original one. On a side note, it is also very interesting to see that in some of the sets, BRIEF and Rotation Invariant BRIEF even outperform the SIFT descriptor (keep in mind that BRIEF is a lot faster to extract and match and also take much less storage space).
To further illustrate the difference in performance between the original and the rotation invariant version of BRIEF, below are recall vs. 1-precision curves for the sets Bikes, Graffiti and Boat, respectively.

Recall vs. Precision curves for the set Bikes – notice that the original, not rotation invariant, version of BRIEF outperforms the rotation invariant version.
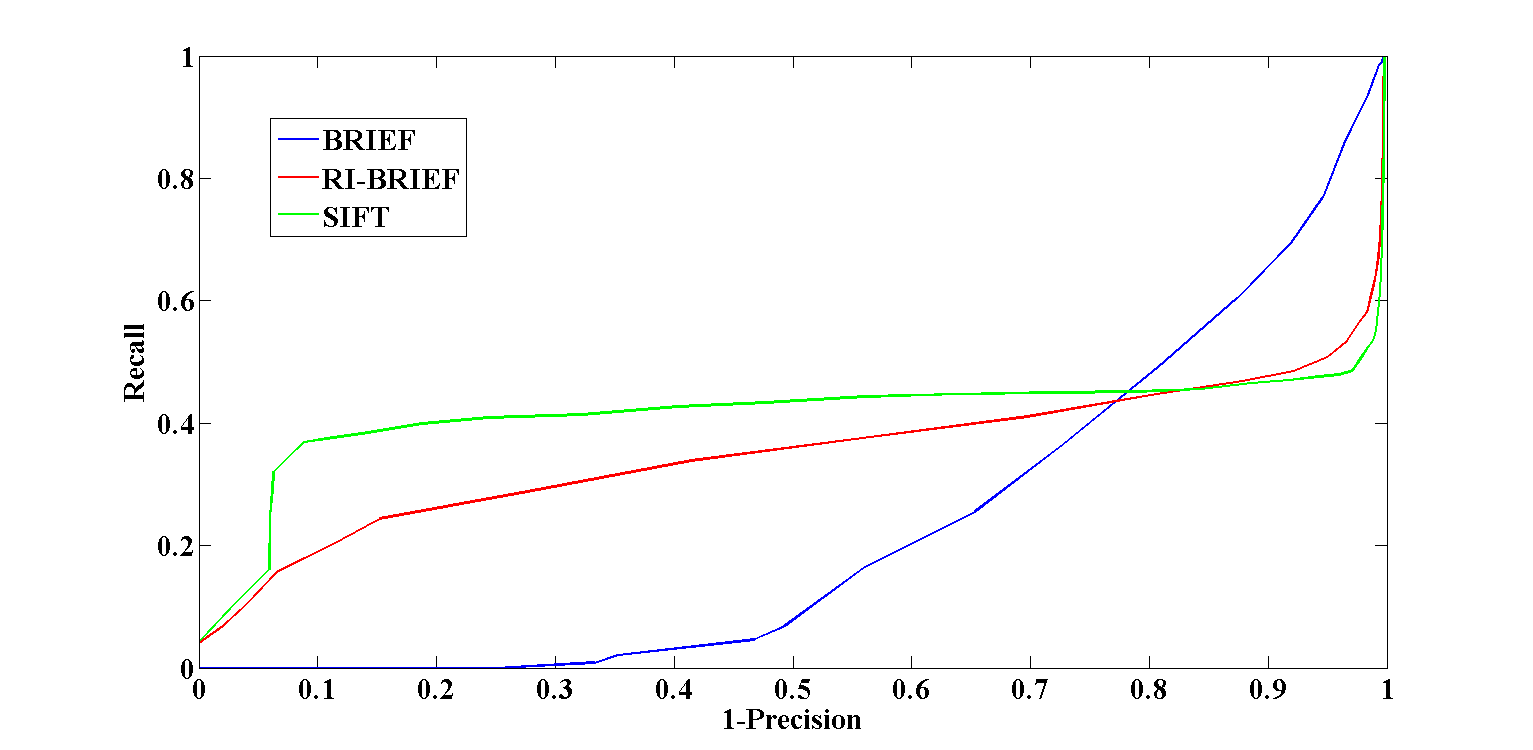
Recall vs. Precision curves for the set Graffiti – notice that since the images depict orientation changes, the proposed rotation invariant version of BRIEF outperforms the original implementation.

Recall vs. Precision curves for the set Boat – notice that since the images depict orientation changes, the proposed rotation invariant version of BRIEF outperforms the original implementation.
Notice again that BRIEF outperforms it’s rotation invariant version in the Bikes sets, which depicts photometric changes (specifically, blur) while the rotation invariant version of BRIEF outperforms the original version in the sets Graffiti and Boat which depict rotation changes.
Adding Rotation Invariant BRIEF to OpenCV
I’m in the process of contributing an implementation of the rotation invariant version of BRIEF to OpenCV. I’ve forked the GitHub OpenCV3.0 repository and implemented the changes under my forked repository.
The code has been further cleaned and is now available under the following pull request: https://github.com/Itseez/opencv_contrib/pull/207
Summary
I have presented a rotation invariant version of BRIEF that makes use of the detector’s estimation of the keypoint orientation in order to align the sampling point of the BRIEF descriptor, thus making it rotation invariant. I’ve demonstrated the advantage of the rotation invariant version of BRIEF in scenarios where orientation changes are present and also it’s disadvantage in dealing with photometric changes (blur, lightning and JPEG compression). Finally, I’ve published a C++ implementation of the proposed descriptor integrating it into OpenCV3.
References
[1] Calonder, Michael, et al. “Brief: Binary robust independent elementary features.” Computer Vision–ECCV 2010. Springer Berlin Heidelberg, 2010. 778-792.
[2] Rublee, Ethan, et al. “ORB: an efficient alternative to SIFT or SURF.” Computer Vision (ICCV), 2011 IEEE International Conference on. IEEE, 2011.
[3] Leutenegger, Stefan, Margarita Chli, and Roland Yves Siegwart. “BRISK: Binary robust invariant scalable keypoints.” Computer Vision (ICCV), 2011 IEEE International Conference on. IEEE, 2011.
[4] Alahi, Alexandre, Raphael Ortiz, and Pierre Vandergheynst. “Freak: Fast retina keypoint.” Computer Vision and Pattern Recognition (CVPR), 2012 IEEE Conference on. Ieee, 2012.
[5] Lowe, David G. “Distinctive image features from scale-invariant keypoints.”International journal of computer vision 60.2 (2004): 91-110.
[6] Bay, Herbert, Tinne Tuytelaars, and Luc Van Gool. “Surf: Speeded up robust features.” Computer Vision–ECCV 2006. Springer Berlin Heidelberg, 2006. 404-417.
[7] Rosten, Edward, and Tom Drummond. “Machine learning for high-speed corner detection.” Computer Vision–ECCV 2006. Springer Berlin Heidelberg, 2006. 430-443.
[8] Mikolajczyk, Krystian, and Cordelia Schmid. “A performance evaluation of local descriptors.” Pattern Analysis and Machine Intelligence, IEEE Transactions on27.10 (2005): 1615-1630.
[9]http://docs.opencv.org/trunk/modules/features2d/doc/common_interfaces_of_descriptor_extractors.html

Cool stuff, glad you are writing again! Would there be any way of knowing in advance which version would perform better for , or would you have to run both and pick the better results?
Also, do you have any intention of posting the performance comparison that you have mentioned in the past?
Hi,
It is always better to test more than one alternative and only then decide on an algorithm. Since the code I wrote follows OpenCV’s common interface for descriptors, it’s very easy to test both of BRIEF’s version in your application.
Having said that, you can estimate in advance in which of BRIEF’s versions you should use. In case that your application is likely to encounter orientation changes between image of the same scene/object – then you should use rotation invariant BRIEF. In case that it’s more likely to encounter photometric changes (e.g. blur and lightning changes), then you should use the original version of BRIEF (with no rotation invariance) since it copes better with those kind of image variations.
Regarding the performance comparison, I’ll actually planning to post it in the following month.
Thank you for your comment.
Gil
Hi Gil,
first of all thanks for your efforts you put in your blog posts.
If i remember correctly you also mentioned in some replies to previous blog posts that you experimented with rotation invariant BinBoost and tried to get this one into opencv too.
What are your experiences with rotation invariant BinBoost compared to BRIEF and BRISK so far?
Did your efforts on BinBoost also make it into your git repo you mentioned above?
I’m just curious, because BinBoosts 64bit length is a really nice property.
Kind regards,
Bogie
Hi,
Thank you for your interesting questions!
Well, I compared the following descriptors and I hope to post my results very soon: BRIEF, ORB, BRISK, FREAK, LDA-Hash, DBRIEF, BinBoost, AKAZE, SIFT and SURF. To make a fair comparison, I enforced rotation invariance on all of the descriptors. I hope to post the results very soon.
Indeed, I integrated BinBoost into OpenCV2.4.9, but it didn’t get into OpenCV. The thing is, that BinBoost depends on external parameters file, so you can’t create a new BinBoost descriptor with default parameters (since the location of the parameters file is not known in advance). I asked in the OpenCV devzone if that acceptable but they never answered. I guess I can just try to make pull request and see if it get’s in or not (but I’ll have to integrate it into OpenCV3 now). I’ll add that to my TODO list:)
By they way, if you like BinBoost for being 64bit length, keep in mind that DBRIEF is only 32 bit length.
Please let me know if you have any other questions.
Best,
Gil.
Something which may prevent the opencv integration and just came to my mind:
The BinBoost code is licensed under GPL, while OpenCV is licensed under BSD.
I don’t know how the non_free stuff of openCV is licensed. (e.g. the SIFT code itself still could be BSD as BSD and patent protection are two completely unrelated things).
So if it would be possible at all to integrate BinBoost it may have to go into the non_free opencv section. Companies who help develop and use OpenCV really don’t want GPL code in there by default, otherwise they would have to make their source code public which is a no go. And even the danger that some GPL code could slip somewhere into a compiled binary is a nightmare.
In contrast the “loading from file” issue may probably not be that severe. I guess the .bin file contains some kind of precomputed tables so it may be possible to make this table part of the source code and compile it directly into the extractor related obj files?!
Regards,
Bogie
Hi,
Licensing can indeed be problematic here, thanks for bringing that up. In any case, I’ll just make a pull request to OpenCV’s repository and let the moderators handle those issues.
Regarding the “loading from file” issue, your suggestion might solve that. I’ll look into it once I’ll make the necessary changes for integrating BinBoost into OpenCV3 (I integrated it into the earlier version – 2.4.9).
Thanks!
Gil
Hi,
Which descriptor would you use for segmentation?
Namely it both patches are form the same object they will be “close” and if are not, on the contrary.
Thank You.
Hi,
I’m not an expert on object segmentation and I’m not sure local descriptors are the best approach.
In any case, I don’t think that you need a rotation invariant descriptor if you are only comparing patches in a single image.
Gil
Pingback: Performance Evaluation of Binary Descriptor – Introducing the LATCH descriptor | Gil's CV blog
Hello Gil,
First of all,
I want to thank you for your efforts you put in your blog posts.
I am a student who interested in doing research about feature descriptor.
Recently, I read your paper : “LATCH: Learned Arrangements of Three Patch Codes.”, and it
really helps me a lot on research.
I recently wrote a program about descriptor evaluation with OpenCV3.0, and wanted to evaluate the difference in performance between different descriptor.
However, i encountered a problem is “how to calculate and draw recall vs 1-precision curve ?” just like the recall vs 1-precision curve in your post. Could you give me some information or teach me?
By the way, my English is not good enough. Sorry about that.
Regards,
Andy
Hi Andy,
Thank you for your interest in my blog.
In our LATCH paper, we have used the evaluation scripts from the following page:
http://www.robots.ox.ac.uk/~vgg/research/affine/
Best,
Gil
Hello Gil,
Thanks for your reply, i followed the page :http://www.robots.ox.ac.uk/~vgg/research/affine/
and i used the evaluation scripts successfully.
But, i have another question.
Although there some detectors and descriptors provided in the page, detectors only updated to
harris-affine detector and descriptors only updated to SIFT.
So, how should i do to evaluation detector (ex. FAST or ORB ) and descriptor (ex. SURF, BRIEF..etc) ?
Thank you very much.
Regards,
Andy
Hi,
In my experiments I extracted descriptors using OpenCV, wrote the results to text files and then used the Matlab evaluation scripts from that page.
Best,
Gil
Hi Gil,
I will try to find a correct way to write the results to evaluate descriptors.
Thanks for your reply and help in these days.
Regards,
Andy
Hi Gil,
After a few days work, i still can’t get the correct data to evaluate descriptor with the scripts provided in the site by Mikolajczyk. I can get the keypoints from detector (e.g. SIFT, ORB…) with openCV, but i don’t know how to get the coefficients of the following equation of the ellipse : a(x-u)(x-u)+2b(x-u)(y-v)+c(y-v)(y-v)=1 with the keypoints i get.
However, I found that openCV2.4.* has a .cpp file call “detector_descriptor_evaluation” but the result i get is weird ( ORB is outperforms than BRIEF in “graf : viewpoint change database” ).
So, I think this evaluation file maybe isn’t suitable for binary descriptors or something i misunderstand.Do you have any suggestion?
I really want to evaluate binary descriptors and produce recall 1-precision curve correctly, i would be appreciated it if you could send your source code to my email : goldengrandson@gmail.com
Regards,
Andy
Hi Andy,
Sorry for the late response and thank you for your interest in my blog.
I just sent you an email.
Best,
Gil
Could you be kind to send me (guangyang89@gmail.com)the evaluation source code you used in LATCH to evaluate the performance of binary descriptors?
Hi Alex,
I used the code from the Oxford lab:
http://www.robots.ox.ac.uk/~vgg/research/affine/desc_evaluation.html#code
Best,
Gil
Hi
I’m working on object detection by using SIFT and SURF in Matlab, and I need to evaluate the precision of these algorithms. can you please help me with your source code?
my e-mail is: mb_tabassom@yahoo.com
thank you
Hi,
I simply used the code from the Oxford lab:
http://www.robots.ox.ac.uk/~vgg/research/affine/desc_evaluation.html#code
Best,
Gil
Hi everyone,
Can i get matlab lab code for brief descriptor. i am facing lot of problem in writing code of brief. openCV codes cant be replicated due to functions used.
Hi,
Thank you for your interest in my blog.
I’m afraid I don’t know of any Matlab implementation of BRIEF (other than the OpenCV code which you can use mex to run from Matlab).
Best.
Gil
Hello Gil.
Great tutorial. I want to implement the CUDA version of rotated BRIEF in OpenCV, I am planning to implement the three stages of the pipeline (detection, description and matching) in CUDA. Do you think this is a feasible project? We also want to parallelize the rotation of key point patch using CUDA.
Do you think this is a feasible project idea? I want to be sure this is not publicly implemented yet.
Thanks.
Fernando Fraga
Hi Fernando,
I’m afraid I don’t have any experience in CUDA programming so I can’t really give a good answer.
However, if you could mail me (gil.levi100@gmail.com) the details of the project, I’ll try to ask one of my colleagues who worked a lot on CUDA implementation of binary descriptors.
Best,
Gil
Hi,
thanks for your work here.
I also want to do some tests and benchmarks of descriptors but i have a problem if i want to use opencv and the oxford benchmarks.
How can i get from an opencv keypoint to the equation of the ellipse: a(x-u)(x-u)+2b(x-u)(y-v)+c(y-v)(y-v)=1 ?
I searched for it, but i didn’t find a good solution.
So how did you solve this problem?
Best Regards,
Simon
Hi,
It’s been a while since we did the experiments, so please forgive me that I’m not a 100% sure, but I think you can get them from the “axes” field in OpenCV keypoint class:
http://docs.opencv.org/trunk/d2/d71/classcv_1_1xfeatures2d_1_1Elliptic__KeyPoint.html#acc9ec69d02052ee9fc5634c2c2ea4534
Best,
Gil